URL Redirect Management at the Edge: Migrations, Domain Forwarding, and Bulk 301s
A redirect map is easy to underestimate until old domains, SEO pages, QR codes, paid campaigns, and app fallbacks all depend on the same URL layer.

The redirect request usually arrives as a small favor.
"Can we point the old domain to the new site?"
"Can the QR code go to the spring offer instead?"
"Can every /blog/2021/... URL move to the new knowledge base before we flip DNS?"
One redirect is rarely the problem. The problem starts when those requests pile up across SEO, paid media, ecommerce, support, app installs, and old domains no one is comfortable turning off. A pricing page still has backlinks. A partner deck still has last year's URL. A campaign domain was printed on packaging. A help article in an onboarding email keeps getting clicks. The same public URL can sit inside Google, a QR code, a sales PDF, a mobile app, and a CRM workflow at the same time.
At that point redirects stop being a server snippet. They become a URL layer that needs ownership.
A URL redirect management platform exists for that layer: import the map, review the rules, preserve paths and query strings, choose the right status code, publish safely, watch what still gets traffic, and roll back when a destination is wrong. Short links cover one slice of that work. UrlEdge is aimed at the larger operational job: redirect management for migrations, domain forwarding, bulk 301 maps, campaign routes, app fallbacks, and teams that need the same source of truth.
Rules in UrlEdge live in a console instead of a forgotten .htaccess file, registrar field, CMS plugin, or one-off CDN rule. Published snapshots run on a Cloudflare-backed edge, so old traffic can be routed before it reaches the origin. That matters when the old app is gone, the campaign is live, and the person who wrote the original server rule is not in the room.
The first sign you need a redirect layer
Most teams do not wake up looking for redirect software. They arrive there after enough "temporary" rules become business-critical.
The pattern is easy to recognize:
- an SEO migration sheet grows from 40 rows to 4,000
oldbrand.com,www.oldbrand.com, andgo.oldbrand.comdo not behave the same way- paid URLs need UTMs and click IDs preserved through the redirect
- app traffic needs iOS, Android, and desktop fallbacks behind one public URL
- a CMS plugin adds a redirect nobody told the infrastructure team about
- a country domain still receives traffic after the regional storefront moved
- launch QA depends on a spreadsheet, a few curl checks, and memory
Google describes redirects as a way to send users and search systems to a new location. That definition is correct, but it hides the operational cost. A five-row map is a configuration task. A multi-domain migration with campaign parameters, bulk 301 redirects, and rollback pressure is release management.
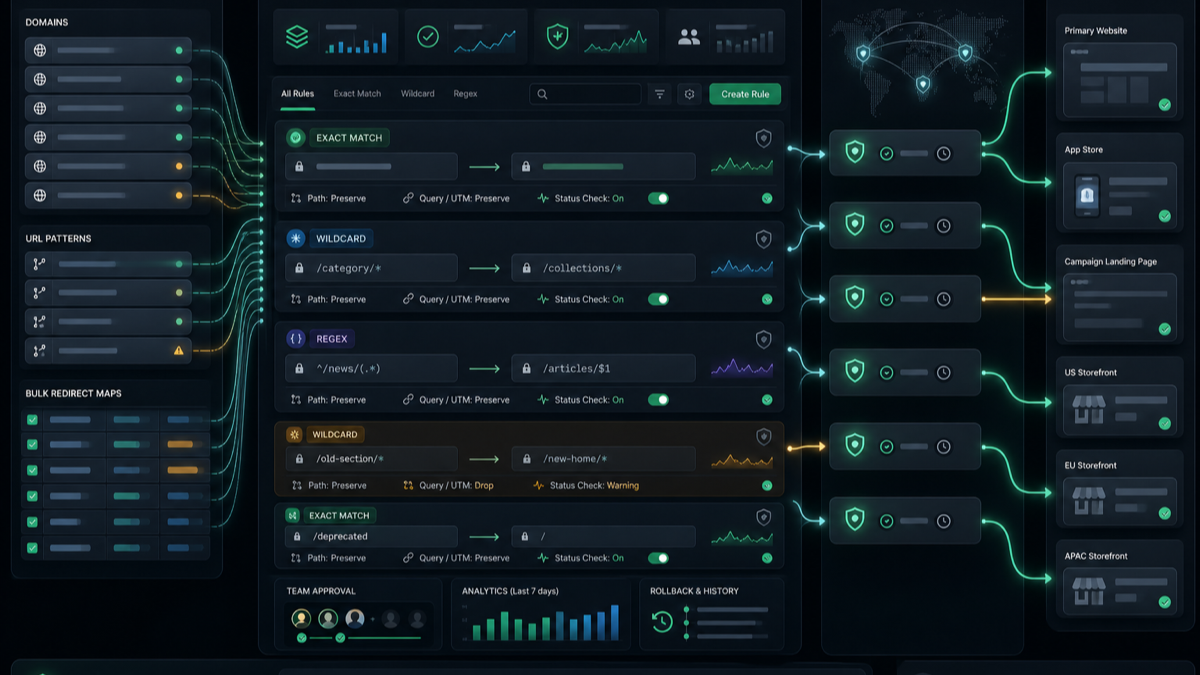
A redirect rule is not the same as redirect management
Nginx can redirect. Apache can redirect. A CMS plugin can redirect. Registrars and CDNs can redirect too.
The useful question is what happens after the rule is live.
| Need | A basic rule can work when | You need redirect management when |
|---|---|---|
| Ownership | One developer owns the site and the risk is low | SEO, growth, ecommerce, support, an agency, and engineering all need a reviewed source of truth |
| Volume | A few URLs changed | You have CSV imports, wildcard rules, regex rules, migration batches, or many domains |
| Behavior | Source A always goes to target B | Path, query, country, device, campaign, or fallback behavior changes by context |
| Risk | A bad redirect is annoying | The URL carries organic traffic, paid spend, QR scans, app installs, affiliate revenue, or customer support traffic |
| Recovery | A server edit can be reverted by hand | You need a previous published snapshot and a clear rollback owner |
| Observability | Nobody needs rule-level reporting | You need to know which old URLs still receive visits and which destinations are failing |
This is why UrlEdge should not be positioned as a dressed-up short link tool. The real competitor is the messy stack teams already use: spreadsheet rows, Nginx snippets, .htaccess, CMS redirects, registrar forwarding, app middleware, CDN page rules, and campaign links that become risky to edit near launch.
The redirect map I would trust on launch week
The usual migration sheet has two columns: old URL and new URL. That is enough to create a redirect. It is not enough to operate one.
A useful redirect map answers questions before people are under pressure:
| Field | What it prevents |
|---|---|
| Source URL or pattern | Ambiguous matching, duplicate rows, and wildcard rules that catch too much |
| Target URL | "Successful" redirects that land on another redirect, a soft 404, or the wrong locale |
| Status code | Permanent 301/308 moves being used for temporary campaigns, or temporary codes being used for durable moves |
| Match type | Exact, prefix, wildcard, and regex rules stepping on each other |
| Path policy | Product and category URLs being dumped onto a root page |
| Query policy | Lost UTMs, click IDs, affiliate IDs, invite tokens, or coupon codes |
| Owner | Rules that no team wants to approve or clean up later |
| Risk tier | High-value SEO pages being treated like low-risk archive cleanup |
| Validation result | Broken targets and loops being discovered by users after launch |
| Rollback target | Emergency fixes turning into more unreviewed redirects |
Those fields can look excessive before a launch. They look normal the first time a paid campaign loses attribution, a top product URL falls into a redirect chain, or a retired domain points to a page that no longer exists.
Website migrations should preserve intent
Bad migration redirects often come from a good instinct: keep old URLs alive. The weaker version sends too many old pages to the homepage because the homepage is easy to approve.
That usually disappoints everyone. Users lose the page they expected. Search engines get a weaker signal. Support teams keep answering questions. Paid and partner traffic may still arrive, but the intent has been erased.
For website migrations, the map should keep the visitor as close as possible to the old purpose:
- Crawl the current site and collect URLs with traffic, backlinks, impressions, revenue, or support value.
- Crawl the staging site or new site.
- Match old URLs to the closest new destination, not merely a convenient destination.
- Mark high-risk URLs: pricing, product, category, docs, support, localized pages, campaign pages, and backlink-heavy content.
- Import the map with Bulk URL Management.
- Validate representative and high-risk routes with Redirect Checker before DNS changes.
- Monitor failed destinations with Broken Link Monitor after launch.
Google's site move guidance notes that larger moves can take longer because Googlebot has to visit the old and new URLs. You cannot schedule that crawl for Google. You can make sure the old URL resolves cleanly, directly, and intentionally when it is crawled.
The real launch day is rarely tidy:
| Time | What often happens |
|---|---|
| Morning | SEO approves the high-value batch, then finds two legacy paths with no replacement |
| Midday | Engineering confirms DNS and HTTPS behavior while one country domain still points to the old storefront |
| Afternoon | Growth checks paid, email, QR, and affiliate URLs with UTMs and click IDs |
| Evening | Support watches old help links, top 404s, and customer-reported dead ends |
This is where a redirect management platform helps without pretending to replace human judgment. It gives the teams one published rule set while the judgment is happening.
Domain forwarding is usually messier than it sounds
"Forward the old domain" sounds like one field until the cases appear:
- Should
oldbrand.com/products/widgetbecomenewbrand.com/products/widget? - Should
http,https, root,www, and subdomains behave the same way? - Should query strings and UTMs pass through?
- Should a country TLD forward to a local store or the global site?
- Should the move be permanent, or is the domain still used in a live campaign?
- Should a retired microsite send every path to one announcement page, or preserve important paths one by one?
Registrar forwarding is often too blunt for this. It may handle the bare domain while missing HTTPS behavior, path preservation, query preservation, subdomains, analytics, or rule review. Server config can handle the details, but then business routing becomes a deployment every time marketing, SEO, or support needs a change.
UrlEdge fits when the domain still carries meaningful traffic: rebrands, acquisitions, country TLD consolidation, legacy microsites, retired product domains, QR campaign domains, app fallback domains, and old domains that keep showing up in reports long after the project was supposed to be finished.
Path and query handling is a policy decision
Path and query preservation should be written down. A checkbox is not enough when attribution and SEO are involved.
| Scenario | Better default |
|---|---|
| Rebrand with the same URL structure | Preserve path and query string |
| CMS migration with changed slugs | Map high-value paths one by one |
| Paid campaign redirect | Preserve UTMs and click IDs |
| Affiliate or partner link | Preserve partner IDs and sub IDs |
| App onboarding or invite flow | Preserve invite tokens only when the destination expects them |
| Cleanup of unsafe public URLs | Allowlist known parameters and drop the rest |
| Old page with no real replacement | Route to a close equivalent, or allow the right 404/410 |
Cloudflare's Bulk Redirects documentation separates source URL, target URL, status code, path suffix preservation, and query string preservation. That separation is practical. In real redirect work, the destination is only part of the rule. The route also depends on how much of the original request should survive.
Why edge execution changes the operating model
Redirects happen before the destination page loads. If an origin server, CMS, or app framework has to process thousands of old URLs only to send visitors somewhere else, the origin is doing work that could have happened earlier.
An edge redirect layer changes the operating model:
- old domains can keep routing after the old application is retired
- migration rules can be published without redeploying the website
- campaign destinations can change without editing application code
- app fallback links can share the same rule inventory as web redirects
- server-side analytics can show which old URLs still receive traffic
- rollback can restore a previous published snapshot instead of inventing a new emergency rule
Application-owned redirects still make sense for product flows, account state, authentication, and in-app logic. SEO migration maps, domain forwarding, campaign redirects, QR links, app-store fallbacks, and legacy URL cleanup usually belong closer to the edge.
QA should prove the route
Import success only proves the file loaded. Redirect QA has to prove what a user, crawler, or paid click will actually experience.

For high-risk rules, check:
- expected status code
- one direct hop to the final URL where possible
- no redirect loop
- final destination status
- path and query preservation
- HTTP to HTTPS behavior
- root,
www, and subdomain behavior - device, country, or language conditions
- owner approval
- rollback route
The post-launch check matters just as much. Destinations drift. Landing pages get unpublished. Products merge into new categories. A CMS plugin adds its own redirect. App-store URLs change. Broken Link Monitor and redirect analytics catch that drift before users, crawlers, or paid clicks become the alerting system.
Where UrlEdge fits
Use UrlEdge when redirect behavior needs to be fast, reviewable, observable, and recoverable.
It is a fit for:
- redirect management across domains, paths, and teams
- bulk URL management for CSV imports and migration maps
- permanent 301 redirects and durable domain moves
- temporary 302 redirects for campaigns and tests
- redirect checking before launch
- geo redirects, device targeting, and advanced redirect rules
- UTM Builder when attribution must survive the redirect
- Link Firewall when paid or partner traffic needs basic abuse controls
The value is operational. SEO can review migration maps. Marketing can change campaign destinations. Engineering can keep brittle routing out of origin config. Leadership can see whether legacy traffic still matters before someone deletes the wrong domain.
Mistakes worth avoiding
Treating 301 as the default answer
Permanent status codes are right for durable moves. They are wrong for temporary campaigns, tests, short-lived app fallback changes, or URLs that may need to revert. Pick the status code from the business intent, not habit.
Sending every missing page to the homepage
Homepage redirects look clean in a spreadsheet. They often fail the user because they erase the original intent. Use the closest equivalent page, a relevant collection, a support article, or a valid 404/410 when there is no replacement.
Adding one more hop every redesign
Do not let old URLs travel through every previous site structure:
http://old.example.com/pricing
-> https://old.example.com/pricing
-> https://www.old.example.com/pricing
-> https://www.new.example.com/pricingUpdate the rule so the old URL points as directly as possible to the final destination.
Letting every team keep a private redirect layer
Nginx, .htaccess, CMS plugins, CDN rules, app middleware, and marketing tools can all redirect. Without ownership, they conflict quietly. A redirect management platform reduces the number of places a business-critical URL can go wrong.
FAQ
What is URL redirect management?
URL redirect management is the work of creating, reviewing, publishing, validating, monitoring, and rolling back redirects across domains, paths, campaigns, apps, and teams. A platform adds ownership, bulk import, analytics, and guardrails around that work.
Is a redirect management platform different from a short link tool?
Yes. Short links are one use case. Redirect management also covers website migrations, domain forwarding, bulk 301 maps, path and query preservation, app fallback routing, monitoring, and team governance.
Should website migrations use 301 or 308 redirects?
Use 301 or 308 for permanent URL moves. 308 preserves method and body, which can matter for non-GET requests. Many SEO migrations use 301, but the status code should still match the request behavior and business intent.
Can UrlEdge replace Nginx or .htaccess redirects?
For many migration, domain forwarding, and campaign redirects, yes. UrlEdge lets teams manage those rules at the edge instead of editing origin server config. Some application-specific redirects may still belong inside the app.
How many redirects can I import?
UrlEdge is designed for bulk redirect workflows: CSV import, validation, publishing, monitoring, and rollback. Volume matters, but review, conflict checks, and post-launch observability matter more.
References
Manage redirects without touching fragile server config
Import bulk redirect maps, preserve paths and query strings, validate every rule, publish at the edge, and keep rollback ready.
Explore redirect managementRelated Articles
View all
www vs apex vs wildcard forwarding without SEO breakage
Host normalization sounds trivial until root, www, subdomains, paths, and query strings disagree. A clean policy keeps the canonical URL stable and avoids redirect chains.

Link Firewall for Paid and Affiliate Traffic: Block Bots, Proxies, and Bad Clicks
Not every bad click is fraud, but every bad click still costs money. A link firewall lets you decide what should happen before paid and affiliate traffic reaches the destination.